声音是怎么被定位的?
——以鸣笛抓拍为例
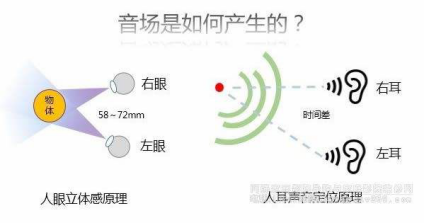
当我们闭上眼睛,仍然能够判断出声音是从哪个方向来的。当然了,前提是两只耳朵都是健康的。如果完全捂住一只耳朵,那么就无法判断声音的具体方位了。这究竟是怎么回事儿呢?
由于两只耳朵存在一定的距离,声源传播到两耳的声音存在频率、强度和时间上的差异。我们就可以利用这些微小的差异进行声源来向定位。现有科学研究表明,哺乳动物更多的是通过感知声音达到的双耳的时间差进行定位。猫可以判断声源位置的最小角度为5°,人在相同情境下的判断精度大约可以达到3°。
显然,如果只有一只耳朵工作,肯定是无法判断声音来自何方了。
1.仿生学、双耳定位和麦克风阵列
仿生学大家一定不会陌生,它是一门既古老又年轻的学科,我们很多应用的科技都是从自然界学到了作用原理或者得到了启发后设计发明出来的。大家耳熟能详的是受鸟儿飞翔的启发发明了飞机、根据蝙蝠的夜间飞行发明了雷达、根据萤火虫发明了冷光……,诸如此类,不一而足。
类似的,在双耳定位的启发下,我们设计了麦克风阵列。利用麦克风来模拟人的耳朵,理论上说,构造包括两个以上麦克风的阵列,就可以实现声音的定位了。但是,人的定位机理更为复杂,可能利用两个麦克风还不够,那就增加麦克风的数量,总能可以达到满意的定位精度。
麦克风阵列是指由两个或多个麦克风按照一定的几何结构排列而成的阵列。按照拓扑结构不同,麦克风阵列可以分为均匀线性阵列、非均匀线性阵列、非线性阵列、环形阵列、平面阵列、立体阵列等。

【阵列类型】
线性阵列可以定位一个角度,即只能定位方位角,无法定位仰角。平面阵列可以定位方位角和仰角,实用性更强,但也意味着更复杂的计算,无法进行定距。立体阵列既可以定向也可以定距。

圆形坐标定向示例(θ1---俯仰角,φ1---方位角)
目前线性阵列和平面阵列是较为常见的两类阵列。线性阵列常见于会议拾音、教室吊麦等;平面阵列在智能音箱、声学照相机等设备中更为常见。立体阵列见于反狙击手系统。

桌面线性麦克风阵列

鸣笛抓拍用麦克风阵列(平面阵列)

反狙击手系统
2.基于麦克风阵列的声学定位
2.1 声学定位基本原理
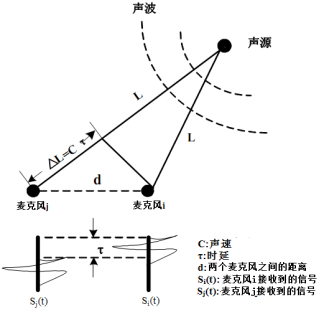
所谓声源定位,就是利用一组按照一定几何位置摆放的麦克风定出声源的空间位置。对于空间中位于不同位置的两个麦克风而言,声源只要不位于它们之间的中线上,那么它们和声源之间的距离就存在差异,如下图所示。可以看出,声源与两个麦克风之间存在距离差△L=Cτ,因此,声波到达两个麦克风的信号在时间上存在时延τ=△L/C。理想情况下,麦克风i和j接收的信号满足关系Si=Sj(t-τ)。
基于麦克风阵列的声源定位技术基本上可以分为4类:基于最大输出功率的可控波束形成技术;高分辨率谱估计技术;基于声压幅度比的定位技术以及基于声音到达时间差(Time Delay of Arrival, TDOA)的定位技术。
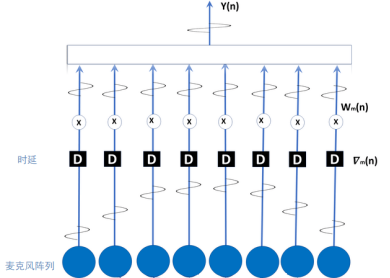
(1) 波束形成技术(Beamforming)
该技术也称为波束成型,这是一种直接定位方法,基本思想是对麦克风所接收到的声音信号加权求和来形成波束,通过调整权值使麦克风阵列的输出功率最大,波束输出功率的点就是声源的位置。传统的波束形成器的权值取决于各阵元上信号的相位延迟,而相位又和时延以及声音的到达时间差有关,故又称为时延求和波束形成器。
假设麦克风的数量为M,第i个麦克风接收到的信号为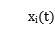 ,对
,对 进行时延对齐后,累加可得
进行时延对齐后,累加可得
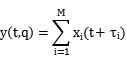
上式中, 指的是当阵列指向搜索点
指的是当阵列指向搜索点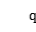 时的可控时延,与麦克风的数量、阵列孔径、声源的入射角以及采样频率成正比,与声音的传播速度成反比。累加输出的功率,即波束的功率为
时的可控时延,与麦克风的数量、阵列孔径、声源的入射角以及采样频率成正比,与声音的传播速度成反比。累加输出的功率,即波束的功率为
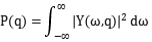
 是
是 的频域表示。声源的位置
的频域表示。声源的位置 可按照下式计算:
可按照下式计算:
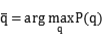
通过控制阵列方向来引导波束,使波束输出功率的点就是声源的位置。
(2) 高分辨率谱估计技术
高分辨率谱估计技术是利用接收信号相关矩阵的空间谱,求解麦克风之间的相关矩阵来确定方向角,进而确定声源的位置。这种定位技术主要包括自相关AR模型法、最小方差(MV)谱估计法和特征值分解算法(如MUSIC算法等)。
高分辨率谱估计技术适合于处理多个声源的情形,但它们都是通过获取麦克风阵列的信号来计算空间谱的相关矩阵。此时,如果所需的矩阵未知,则须通过已得到的数据进行估计,这要求空间中的声源或噪声须平稳时不变,这在实际中很难实现;此外,该方法的计算量大,在声源定位系统中的应用不多见。
(3) 基于声压幅度比的定位方法
该方法利用不同麦克风接收的来自于同一个声源的声音信号在强度上的差异来实现声源定位。根据由声压在麦克风处产生的电压输出与对应声源到麦克风的距离两者之间存在的关系导出一个用于声源定位的约束条件。由这个约束条件可确定三维空间中的一个球面。每个麦克风可以导出这样一个约束条件,利用这些约束条件可确定出声源的位置。它们既可以是单独使用,也可以和由基于时间差的方法导出的约束条件一起使用。
(4) 基于声音到达时间差的声源定位技术
基于声音到达时间差(TDOA)估计的定位方法精度相对较高,计算量小,适合于实时实现。基于TDOA的定位方法是一种两步方法。第一步,开展TDOA估计,获得麦克风阵列中相对阵元之间的TDOA。估计TDOA的方法有很多,大致可以分为互相关方法、广义互相关方法、自适应滤波器法、互功率谱相位法和高阶统计量法等。第二步,利用估计得到的相对阵元之间的时间差,结合已知的麦克风阵列的空间几何关系确定声源的位置。这种方法实时性较好,但存在误差传递放大、无法进行多声源定位等问题。
2.2 定位用麦克风阵列的性能指标
麦克风阵列的性能指标包括主瓣宽度(波束宽度)、旁瓣增益、阵列增益等。从定位的角度出发,阵列增益是无关的性能指标,需要考虑主瓣宽度和旁瓣增益这两个指标。

波束图示例
上面给出了一个波束图示例,这是一个由12个麦克风组成的均匀线性阵列,阵列间距d=8cm,声源入射角度为阵列侧边正前方(即90°的位置),声源频率f=2000Hz。上图共包括11个波束,具有大幅度的波束称为主瓣(声源所在方向),其他都是旁瓣。主瓣宽度定义为主瓣两边的两个第一过零点之间的范围,上图的主瓣宽度大约是20°。旁瓣增益指的是旁瓣高度,上图的旁瓣增益大约是-12dB。
旁瓣增益越低,对于目标方向以外的干扰噪声的抑制能力就越强,可以更好的降低目标检测的虚警概率,对于鸣笛抓拍而言,就是不会出现“虚像”。比如,视野范围之外有车辆鸣笛,它所产生的“虚像”可能恰好位于视野范围之内,这样就容易造成“假定位”,无法区别视野范围内外的鸣笛车辆。主瓣宽度越小,目标方向的分辨能力越强,阵列的指向性越好。对应于鸣笛抓拍,就意味着光斑越准确,不会出现一个光斑覆盖多台车辆的情况。
通常情况下,在麦克风数量相同的情况下,麦克风分布形式越规则,主瓣宽度和旁瓣增益会越大。下面给出了两个麦克风阵列构型,都由32个麦克风构成,从对应波束图中可以明显看到这一规律。因此,在设计麦克风阵列时,应该尽可能地设计优化构型,而不是选择均匀的规则构型。
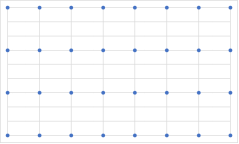

规则型阵列及其波束图
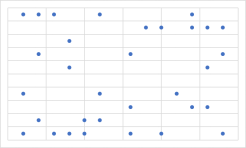

非规则型阵列及其波束图
3.应用案例:鸣笛抓拍系统
基于麦克风阵列的声音定位技术已经在工程领域中得到了广泛应用,典型包括异常声响定位的声学照相机、飞机飞跃噪声分析使用的大型地面阵列、战场中的狙击手定位系统等。
目前,得到广泛应用的声学定位技术莫过于交通领域中的鸣笛抓拍系统了,实际上这也是声学照相机的一个具体应用。纵观市场上已有的鸣笛抓拍系统,基本都是由一个平面麦克风阵列、一个电警(卡口)相机和主机组成,麦克风阵列用于鸣笛声音定位、相机用于识别鸣笛车辆车牌并抓拍图片生成证据。

世邦鸣笛抓拍系统
系统的整个抓拍流程如下图所示。在前端,系统捕获到机动车鸣笛声音,启动定位分析软件进行定位,如果定位结果位于抓拍视野范围内,则启动高清相机进行抓拍;根据定位坐标,进行相关车辆的车牌识别,如果能够识别出符合要求的车牌,则将车牌推送到LED屏显示,同时生成完整证据链,包括车牌图片及识别结果、车辆特写、车辆全景、鸣笛云图、鸣笛声纹图和鸣笛过程的音视频(叠加云图),并将其推送到后台。
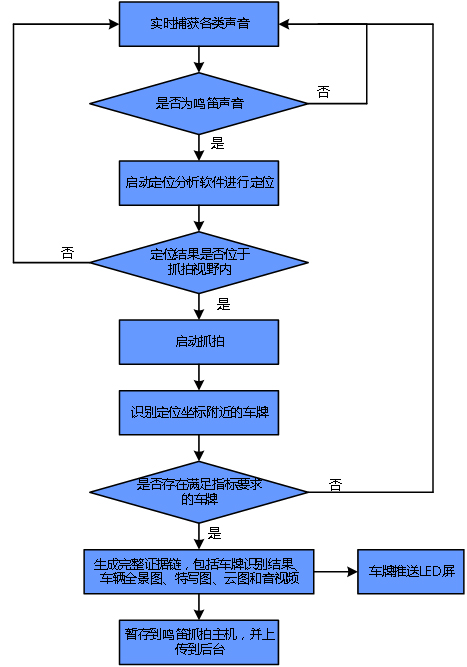
鸣笛抓拍工作流程
系统计算监测路面有效探测区域的声音大小分布,用颜色表示声音相对大小生成声音分布图,声音分布与高清图片叠加形成声音云图,对鸣笛声连续采集分析,持续生成声音云图,声音云图叠加到视频上连续播放生成“声音视频”;同时,自动生成4张图片(违法时刻车辆全景图、全景云图、车辆特写图和车牌特写与鸣笛频谱图)和音视频证据,其证据支持添加水印信息、防伪信息。证据信息如下图所示。

鸣笛抓拍记录证据
鸣笛抓拍FAQs:
Q1:前后车紧邻,后车车牌被遮挡,后车鸣笛,是否会误抓前车?
A1:不会。首先在算法上进行处理,如果两车距离特别近,后车鸣笛声音会被前车遮挡,到达声呐阵列已经不是直达波,可以在定位算法上排除这种定位结果,不予定位抓拍;其次,通过对抓拍图像的结构化处理,设计合适的定位光斑与车辆方框的“容纳”算法,可准确判断鸣笛光斑所在车辆位置。
Q2:机动车紧邻一侧有电动车/摩托车鸣笛,是否会误拍机动车?
A2:不会。对抓拍图像进行结构化处理,可以准确区分出电动车/摩托车、机动车、自行车等,根据定位光斑的位置,可以准确判断出鸣笛来自于电动车/摩托车。
Q3:多车同时鸣笛,如何处理?
A3:如果多台车在同一时刻按下喇叭,又在同一时刻松开喇叭,那么这段时间只会定位一台鸣笛车辆;如果两台车的按喇叭时刻前后相差数十毫秒以上,系统可以定位到两台车辆。
Q4:车辆鸣笛后快速驶离,能否快速反应准确抓拍?
A4:能。世邦鸣笛抓拍系统创新采用了“预抓拍”技术,预留一个数秒左右的抓拍图片缓冲区,当鸣笛发声并定位之后,会综合考虑声音传播时间、定位所需的笛声时长,从缓冲区中提取出接近鸣笛时刻的图片作为证据图片,能够准确定位鸣笛车辆。实验表明,时间误差在±20ms的范围,以60km/h的市区时速计算,折算距离误差为±30cm,不会对定位车辆结果产生影响。


 金融
金融
 教育
教育
 司法
司法
 公安
公安
 交通
交通
 平安城市
平安城市
 智慧建筑
智慧建筑
 景区
景区
 工业
工业
 政务及其他
政务及其他



