
时间:2022-04-27 来源:原创 人气:6567
1.基本概念
爱人的气息是从不失职的温柔路标,我们总能够在一群人中一眼看到自己的爱人;同样,爱人的声音也总是那么独特,在鼎沸的人声中那么清晰。听到TA的声音后,其他一切声音都已经被屏蔽了,一声入耳,再无其他。
这就是人所谓的定向拾音的能力,当然这个比方不那么恰当。实际上这是经常听说的“鸡尾酒会效应”,指的是人能够在复杂的升学环境中将注意力集中到某个人身上,并且忽略掉背景噪声和其他人的声音。这是人的听觉选择能力,涉及到双耳结构以及复杂的大脑处理机制。
2.实现原理和方式
目前,利用麦克风模拟这种定向拾音能力,已经有了一定的成果。从实现方式上来看,可以分为单通道麦克风和多通道麦克风(麦克风阵列)两种方式。
2.1 单通道麦克风
利用单通道麦克风实现定向拾音,指的是采用单指向性麦克风拾取单一方向声音。麦克风的指向性指的是麦克风从指定方向拾取声音,包括心型、超心型、全向星和8字型等拾音模式。
2.1.1 心型模式
拾音模式一个心型的图案,通常被用在工作室录制人声中,是歌手较喜欢的麦克风。适用于不想拾取观众的声音或者从监控器中传出的声音。在工作室中,使用心型麦克风可以有效的降低环绕声和麦克风反射回来的声音。拾音模式如图1所示。理论上说,这种心型模式的拾音前后比可达到20dB以上,实际测试结果显示,常见的信心模式麦克风能达到10dB已经是很好的表现了。
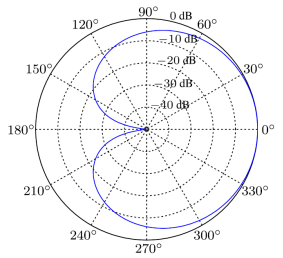
图1 心型拾音模式
这种指向性的麦克风的拾音模式如图2所示,在舞台上它们能够更好的收录主唱的声音,并且阻挡周围乐队的声音,其缺点是也会收录一些麦克风后面的声音。这就意味不应该将你的监听音箱放在面前(一般情况下120或者240度的位置较好)。超心型话筒的指向性比心型更窄,特别适合近距离拾音。

图2 超心型模式
2.1.3 全向型模式
这就是常见的无指向性麦克风,对所有角度都有相同的灵敏度,这意味着它可以从所有方向均衡地拾取声音。这种麦克风完全没有指向性,不能用于定向拾音的场合。

图3 全向型模式
2.1.4 8字型模式
顾名思义,8字型麦克风的拾音形状类似数字8,也叫双心型麦克风或也被叫做是双指向形,它们通常被用在工作室而不是现场,而且大部分此类麦克风都是铝带式麦克风。它们从前方和后发拾取声音,而不是从两侧。这种是在正面和背面较灵敏左右测不够灵敏,因为这种指向类型的话筒对来自话筒正前方和正后方的音频信号具有同样高的灵敏度,但是对来自话筒侧面的信号不太敏感。

图4 8字型拾音模式
采用单通道麦克风实现定向拾音,可以实现一定程度上的定向效果,但对其他方向上的干扰抑制能力是远远不够的。我们只想听到TA的声音,但这种单指向性的麦克风做不到这一点,第三者、第四者乃至更多的声音都会不可避免地泄漏进来。因此,需要采用更好的设计方案,即多通道麦克风(麦克风阵列)方案,实现更好的定向拾音效果。
2.2 麦克风阵列方案
麦克风阵列是由按照特定的拓扑结构分布在空间的多个麦克风组合而成。与单个麦克风相同,麦克风阵列为一个整体,仍然可以看作一个复杂的传感器,作为声音与拾音系统的接口模块;但不同的是,麦克风阵列不但可以获得声音信号的时域信息还可以获得空域信息。麦克风阵列信号处理的主要目标是尽可能地利用空时信息来提高接收端信号的质量。
在使用麦克风阵列对语音信号进行处理的发展历程中,产生了许多阵列结构,包括结构相对简单的直线阵列、平面阵列以及复杂的三维球阵列。图5给出了N个麦克风等间距直线阵列的模型,θ为声源的方位角。

图5 直线阵列模型
在定向拾音中,直线阵列是较常见的结构。对应两种拾音模式:端射和宽边模式。简单地说,端射模式的拾取方向是阵列轴线方向,而宽边模式拾取的方式是与阵列轴线垂直的方向。
2.2.1 端射模式
较常见的端射模式实现方式为微分麦克风阵列,有时候也称为差分麦克风阵列。差分阵列表现的是空间声压的差异性,声压的一阶差分可以由两个相近放置的全向麦克风输出相减得到,同理,N个麦克风可以获得声压的N-1阶差分。
下面以图6所示的两麦克风组成的差分阵列为例,介绍差分阵列的定向拾音模式的设计思路。两麦克风组成的差分阵列,对应的是阶次为1,有两个设计约束条件:
1.在目标方向无失真(θ=0°时,拾音增益为1);
2.在0°<θ≤180°的范围内存在一个零陷。

图6 一阶差分阵列
令 表示麦克风阵列的导向矢量,以图6所示的阵列为例,导向矢量为
表示麦克风阵列的导向矢量,以图6所示的阵列为例,导向矢量为

设计目标就是为两个麦克风选择合适的权重 ,满足上面的两个约束条件,即
,满足上面的两个约束条件,即

以心型模式为例,可求解得到权重h(ω):

对 取泰勒近似,可将上式近似改写为
取泰勒近似,可将上式近似改写为

 并与麦克风1的信号相减之后,再进行一个低通滤波的结果。显然,差分麦克风阵列体现的是一种“延迟相减”的思路,将不希望拾取的信号通过相减的方式抵消掉。
并与麦克风1的信号相减之后,再进行一个低通滤波的结果。显然,差分麦克风阵列体现的是一种“延迟相减”的思路,将不希望拾取的信号通过相减的方式抵消掉。GSC方法由两条支路组成,如图7所示,上面的支路固定波束形成器(Fixed Beamformer,FBF)支路,一般由DSB算法实现,用以增强目标方向信号,抑制其他方向的干扰;下面一条支路由阻塞矩阵(Blocking Matrix,BM)和自适应干扰抵消器(Adaptive Interference Canceler,AIC)两部分组成,阻塞矩阵用以获得目标信号零陷位置的参考噪音信号,该信号与DSB输出中的噪音信号相关,自适应干扰抵消器利用该参考噪音信号估计DSB输出中的噪音信号,并从DSB输出信号中减去该估计信号,得到波束形成输出信号。

图7 GSC算法结构
在二元麦克风小阵列中,由于两个阵元间距较小,它们的脉冲响应函数可以近似的认为是相等的或者其差别可以忽略不计。由图6可知,第二个麦克风相对于第一个麦克风的目标信号相位差为 ,DSB方法就是对两路麦克风信号进行时间上的对齐(即频域的相位补偿),对应DSB输出为:
,DSB方法就是对两路麦克风信号进行时间上的对齐(即频域的相位补偿),对应DSB输出为:

阻塞矩阵BM按照如下方式定义:

计算语音存在先验概率:

其中, 表示频点k所对应的相位差,即
表示频点k所对应的相位差,即

 表示取相位。需要注意的,相位差
表示取相位。需要注意的,相位差 需要解卷绕到(-π,π]的区间中。
需要解卷绕到(-π,π]的区间中。 表示相位差阈值,fs表示采样频率(Hz)。
表示相位差阈值,fs表示采样频率(Hz)。考虑到相邻频点之间存在高度的相关性,因此,可以对相邻频点的语音存在概率进行平滑,提高频率计算结果的准确性和相邻帧之间结果的连续性。平滑后的各频点语音存在先验概率如下所示:

其中,w(i),i=0,1,...,I-1表示Gammatone滤波器系数,I为Gammatone通道的数量,典型值为I=20或40等,根据具体需求而定。按照下式进行计算:

 表示两路通道的信号均值。Hi(k),i=0,1,...,I-1表示Gammatone滤波器曲线的采样值。
表示两路通道的信号均值。Hi(k),i=0,1,...,I-1表示Gammatone滤波器曲线的采样值。 作为单通道语音信号,按照常见的噪声谱估计方法,如最小值追踪方法等,计算
作为单通道语音信号,按照常见的噪声谱估计方法,如最小值追踪方法等,计算 对应的噪声功率谱,用λ(k)表示。
对应的噪声功率谱,用λ(k)表示。计算后验信噪比:

求语音存在的先验概率的均值,以此作为判断单帧信号是否存在语音的一个标识:

求语音不存在后验概率q(k):

 表示先验概率均值的阈值,与拾音范围角度的大小有关系,当确定了拾音范围角度之后,方可确定这个阈值。
表示先验概率均值的阈值,与拾音范围角度的大小有关系,当确定了拾音范围角度之后,方可确定这个阈值。 表示后验信噪比的最大值,取4~5之间的值,可取得较好的调试结果。
表示后验信噪比的最大值,取4~5之间的值,可取得较好的调试结果。计算处理后的语音:


3.应用
定向拾音技术的应用比较广泛,较常见的应用场合是本地扩声。在本地扩声中,由于定向拾音技术可以压制某个方向上的声音,因此可以将播音设备放置在这个方向,能够很大程度上抑制可能发生的啸叫,从而解决困扰本地扩声的较大问题之一,在教室、会场等扩声场景中都有很大的应用潜力。此外,该技术在存在角色分离录音要求的场合也都有潜在的应用空间。

扫一扫加好友咨询